LangChain: Questions and Answers
This document has been translated using machine translation without human review.
Information is current for langchain v0.3.15 and Python v3.13.
How to install LangChain?
pip install llama-cpp-python
pip install langchain langchain-community langchain-core
How to create a simple chat using LangChain?
from langchain_community.chat_models import ChatLlamaCpp
llm = ChatLlamaCpp(
model_path="llama-3.2-1b-instruct-q8_0.gguf",
Verbose=False,
)
while True
question = input("User: ")
if question in ("end", "exit", "quit", "stop"):
exit()
response = llm.invoke(question)
print(f"Assistant: {response.content}")
How to add an instruction (prompt) for the model in LangChain?
from langchain_community.chat_models import ChatLlamaCpp
from langchain_core.prompts import ChatPromptTemplate
system_prompt = (
"You are an assistant who strictly follows the following instructions: "
"1. If I ask you to turn on the light, you answer 'exec light_on'."
"2. If I ask you to turn off the light, you answer 'exec light_off'."
"Don't change the text in quotation marks. Don't add anything extra."
)
prompt = ChatPromptTemplate.from_messages(
[
("system", system_prompt),
("ai", "I'm ready!"),
("human", "{input}"),
]
)
llm = ChatLlamaCpp(
model_path="llama-3.2-1b-instruct-q8_0.gguf",
verbose=False
)
chain = prompt | llm
while True:
question = input("User: ")
if question in ("end", "exit", "quit", "stop"):
exit()
response = chain.invoke({"input": question})
print(f"Assistant: {response.content}")
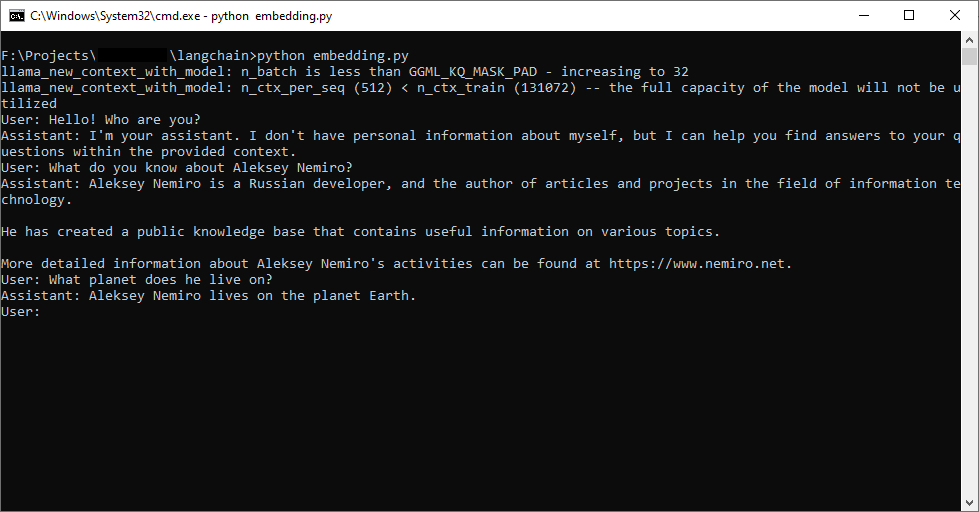
How to use local data embedding in LangChain with the llama.cpp server?
Using llama-server is a simple and relatively inexpensive method in terms of computer resource consumption.
The OpenAI and FAISS packages are required:
pip install openai faiss-cpu
For FAISS, there are separate packages for CPU and GPU.
If an error occurs like: module 'openai' has no attribute 'error'
Try using an older version of the OpenAI package:
pip install openai==0.28.1 --upgrade --force-reinstall --no-cache-dir
Create or prepare a data file. For example, in text format:
<s>Earth is the third planet from the Sun and the only astronomical object known to harbor life.
Aleksey Nemiro lives on this planet.</s>
<s>Aleksey Nemiro is a Russian developer, author of articles and projects in the field of information technology.
It has a public knowledge base that contains useful information on various topics.</s>
<s>Aleksey Nemiro's knowledge base is located at https://kb.nemiro.net</s>
<s>More detailed information about Aleksey Nemiro's activities can be found at https://www.nemiro.net</s>
Start the embedding server:
llama-server -m "Meta-Llama-3.1-8B-Instruct-Q8_0.gguf" --embedding --pooling cls --port 8082
Use the following script to run a local model with embedding your own data:
import os
from langchain_community.document_loaders import TextLoader
from langchain_community.chat_models import ChatLlamaCpp
from langchain_core.prompts import ChatPromptTemplate
from langchain_community.embeddings import LocalAIEmbeddings
from langchain_community.vectorstores import FAISS
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain.chains import create_retrieval_chain
text_loader = TextLoader("data.txt")
documents = text_loader.load_and_split()
if not os.environ.get("OPENAI_API_BASE"):
os.environ["OPENAI_API_BASE"] = "http://localhost:8082/v1" # your embedding server address
if not os.environ.get("OPENAI_API_KEY"):
os.environ["OPENAI_API_KEY"] = "1234567890" # random string here
embeddings = LocalAIEmbeddings()
db = FAISS.from_documents(documents, embeddings)
retriever = db.as_retriever()
system_prompt = (
"You are an assistant who answers questions using the provided context.\n"
"\n\n"
"{context}"
)
prompt = ChatPromptTemplate.from_messages(
[
("system", system_prompt),
("ai", "I'm ready!"),
("human", "{input}"),
]
)
llm = ChatLlamaCpp(
model_path="Meta-Llama-3.1-8B-Instruct-Q8_0.gguf",
# n_gpu_layers=-1, # to use gpu
# n_threads=6,
verbose=False
)
combine_docs_chain = create_stuff_documents_chain(llm=llm, prompt=prompt)
chain = create_retrieval_chain(retriever, combine_docs_chain)
while True:
question = input("User: ")
if question in ("end", "exit", "quit", "stop"):
exit()
response = chain.invoke({"input": question})
answer = response["answer"]
print(f"Assistant: {answer}")
How to use local local data embedding in LangChain with Sentence Transformer?
1. Install the sentence-transformers package:
pip install sentence-transformers
2. Download model all-MiniLM-L6-v2.
3. Create a class derived from Embeddings:
from langchain_core.embeddings import Embeddings
from sentence_transformers import SentenceTransformer
from typing import List
class SentenceTransformerEmbeddings(Embeddings):
def __init__(self, model_path: str):
self.model = SentenceTransformer(model_path)
def embed_documents(self, texts: List[str]) -> List[List[float]]:
return [self.model.encode(t).tolist() for t in texts]
def embed_query(self, text: str) -> List[float]:
return self._embedding_func(text)
async def aembed_query(self, text: str) -> List[float]:
return await self._aembedding_func(text)
def _embedding_func(self, text: str) -> List[float]:
return self.model.encode(text).tolist()
4. Use the created class for embedding:
embeddings = SentenceTransformerEmbeddings(
model_path="path to all-MiniLM-L6-v2 here"
)
db = FAISS.from_documents(documents, embeddings)
retriever = db.as_retriever()
How to use Qdrant?
pip install langchain_qdrant
from langchain_qdrant import QdrantVectorStore
from qdrant_client import QdrantClient
from qdrant_client.http.models import Distance, VectorParams
# embeddings = for example SentenceTransformerEmbeddings
vector_size = embeddings.model.get_sentence_embedding_dimension()
qdrant_client = QdrantClient(
path="path to data storage",
)
if qdrant_client.collection_exists("my-collection"):
qdrant_client.delete_collection("my-collection")
qdrant_client.create_collection(
collection_name="my-collection",
vectors_config=VectorParams(size=vector_size, distance=Distance.COSINE),
)
db = QdrantVectorStore(
client=qdrant_client,
collection_name="my-collection",
embedding=embeddings,
)
db.add_documents(documents)
How to embed a file in JSON Lines format?
pip install jq
from langchain_community.document_loaders import JSONLoader
loader = JSONLoader(
file_path="my_data.jsonl",
jq_schema=".completion",
text_content=False,
json_lines=True,
)
data = loader.load()
print(data)
How to create a custom class for text splitting (text splitter)?
The following code shows an example implementation of a custom text splitter for LangChain.
The code splits the text by llama tokens <s></s> (BOS + EOS) and passes it through RecursiveCharacterTextSplitter.
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.text_splitter import TextSplitter
from langchain_core.documents import Document
from typing import List, Optional
import copy
class InstructTextSplitter(TextSplitter):
def __init__(self, chunk_size=512, chunk_overlap=200):
self._add_start_index = True
self.recursive_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap
)
def split_text(self, text: str) -> List[str]:
splits = text.split("</s>")
splits = [s.replace("<s>", "").strip() for s in splits if s.strip()]
splits = [s for s in splits if s]
final_chunks = []
for s in splits:
chunks = self.recursive_splitter.split_text(s)
final_chunks.extend(chunks)
return final_chunks
# to fix: https://github.com/langchain-ai/langchain/issues/16579
def create_documents(self, texts: List[str], metadatas: Optional[List[dict]] = None) -> List[Document]:
_metadatas = metadatas or [{}] * len(texts)
documents = []
for i, text in enumerate(texts):
index = 0
for chunk in self.split_text(text):
metadata = copy.deepcopy(_metadatas[i])
if self._add_start_index:
metadata["start_index"] = index
index += len(chunk)
new_doc = Document(page_content=chunk, metadata=metadata)
documents.append(new_doc)
return documents