Flowise
Flowise — визуальный конструктор приложений LLM без написания кода.
Как внедрить собственные данные в LLM?
Внедрение данных — это предоставление доступа к данным через контекст модели.
Это простой способ обучения больших языковых моделей, который не требуется серьезных технических ресурсов.
Если что-то не понятно, попробуйте взглянуть на скриншоты внизу страницы.
примечание
Информация актуальна для Flowise v2.2.4.
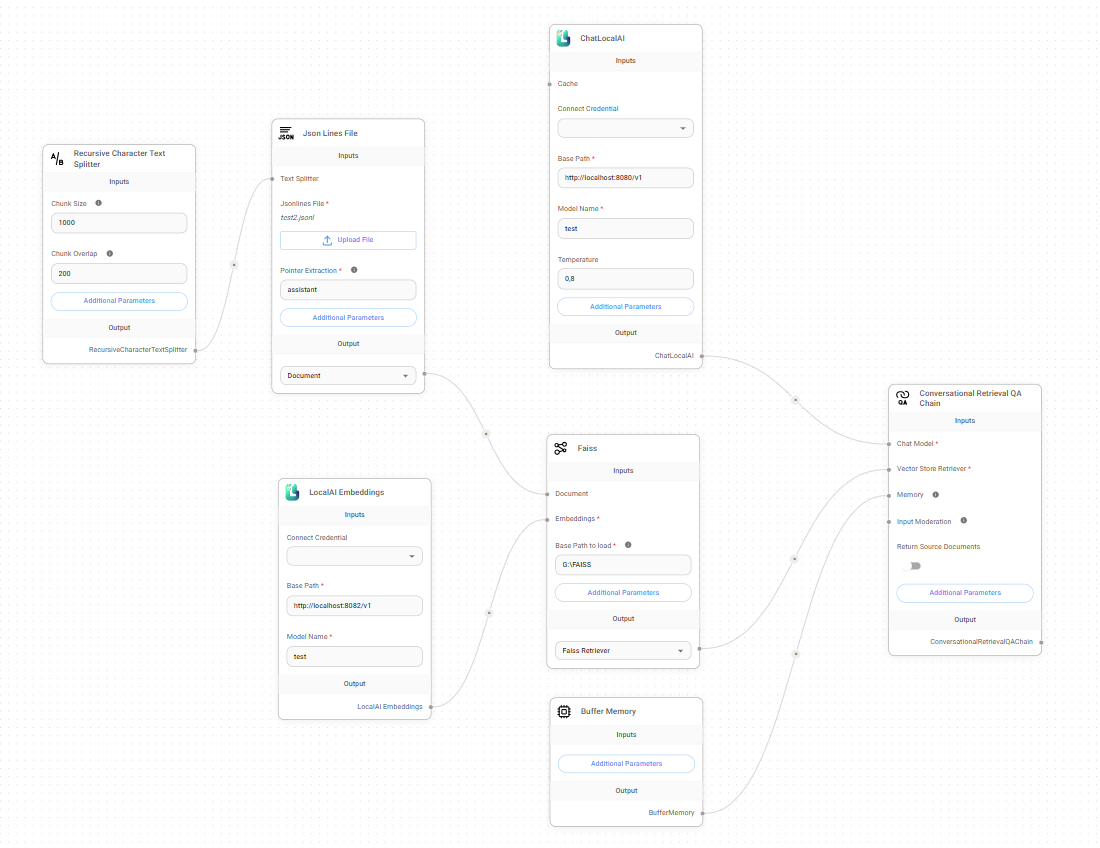
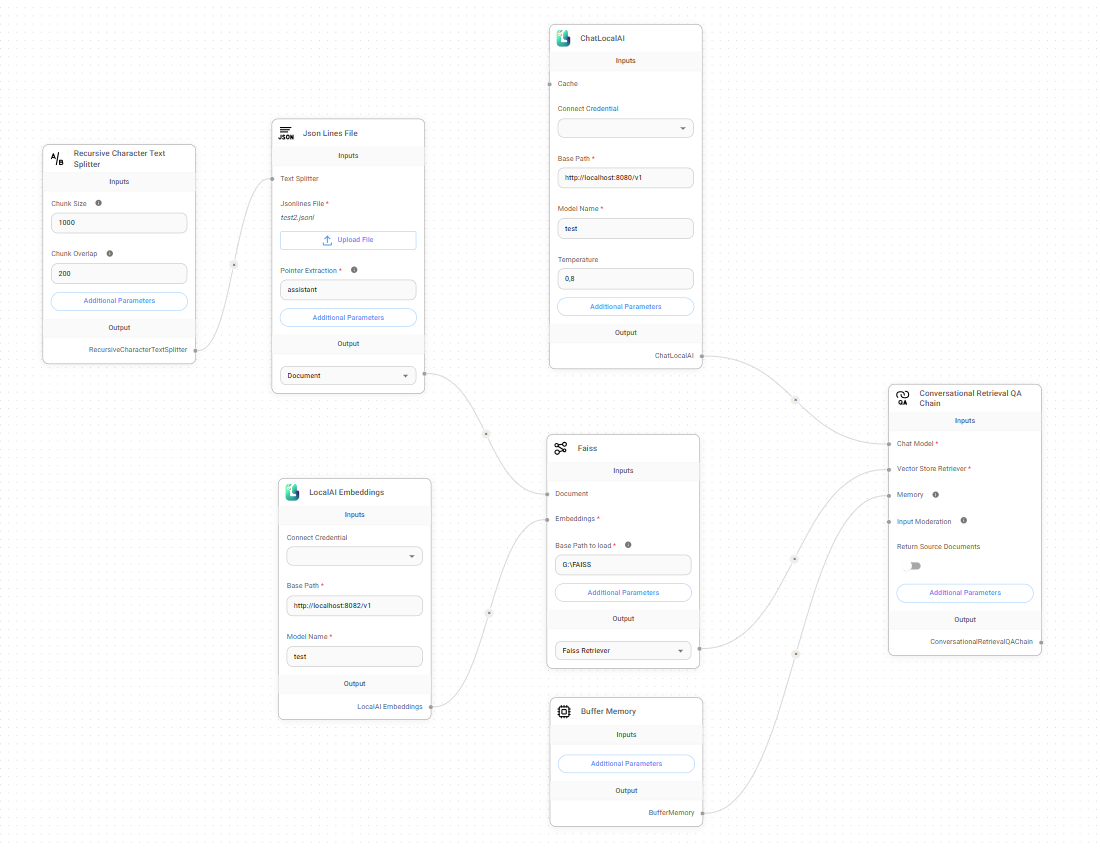
- Откройте раздел Chatflows и нажмите Create.
- Выберите LangChain в качестве набора компонентов.
- Добавьте Conversational Retrieval QA Chain.
- Добавьте любой загрузчик документов - Documents Loader. Например,
- Text File для текстовых файлов:
- Загрузите любой текстовой файл, данные которого будут внедрены в контекст.
- Json Lines File для файлов
.jsonl:- Загрузите набор данных в формате JSON Lines.
- Укажите в параметре Pointer Extractor имя поля в JSON, которое содержит ответ помощника.
- и т.д.
- Text File для текстовых файлов:
- Добавьте Text Splitter. Например,
- Markdown Text Splitter для файлов в формате markdown;
- Recursive Character Text Splitter для файлов в формате JSON Lines;
- и т.д.
- Соедините Text Splitter и Documents Loader.
- Добавьте LocalAI Embeddings - это позволит интегрировать данные в модель:
- В параметре Base Path укажите URL к серверу внедрения (embedding server). Например, при использовании llama.cpp:
- Если запущен llama-server в режиме внедрения:
llama-server.exe -m "C:\models\Meta-Llama-3.1-8B-Instruct-Q8_0.gguf" --embedding --pooling mean --port 8082 --verbose, то в таком случае, в параметре Base Path должен быть адресhttp://localhost:8082/v1.
- Если запущен llama-server в режиме внедрения:
- Укажите любое имя модели в параметре Model Name. Например,
test.
- В параметре Base Path укажите URL к серверу внедрения (embedding server). Например, при использовании llama.cpp:
- Добавьте любой Vector Store:
- In-Memory Vector Store - самый простой вариант для первой пробы.
- Faiss - локальная векторная база от Facebook, ничего сложного, главное установить правильную версию:
- В параметре Base path to load укажите путь папке хранилища.
- Соедините Documents Loader и Embedding с Vector Store.
- Добавьте ChatLocalAI - это позволит использовать локальные LLM:
- В папаметр Base Path укажите URL сервера воспроизведения (inference server). Используйте модель аналогичную модели серера внедрения. Например, при использовании llama.cpp:
- Если llama-server запущен со следующими параметрами:
llama-server.exe -m "C:\models\Meta-Llama-3.1-8B-Instruct-Q8_0.gguf" --port 8080 --verbose, то в параметр Base Path следует указать адресhttp://localhost:8080/v1.
- Если llama-server запущен со следующими параметрами:
- Укажите в параметр Model Name имя модели аналогичное имени указанному в узле LocalAI Embeddings.
- Соедините ChatLocalAI и Vector Store с Conversational Retrieval QA Chain.
- Сохранить рабочий процесс чата.
- Убедитесь, что сервера внедрения (embedding server) и воспроизведения (inference server) запущены.
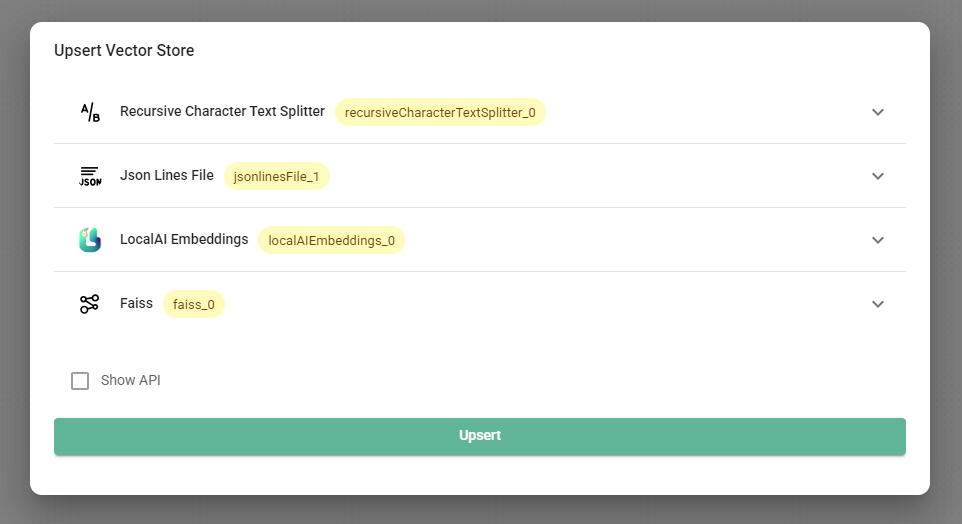
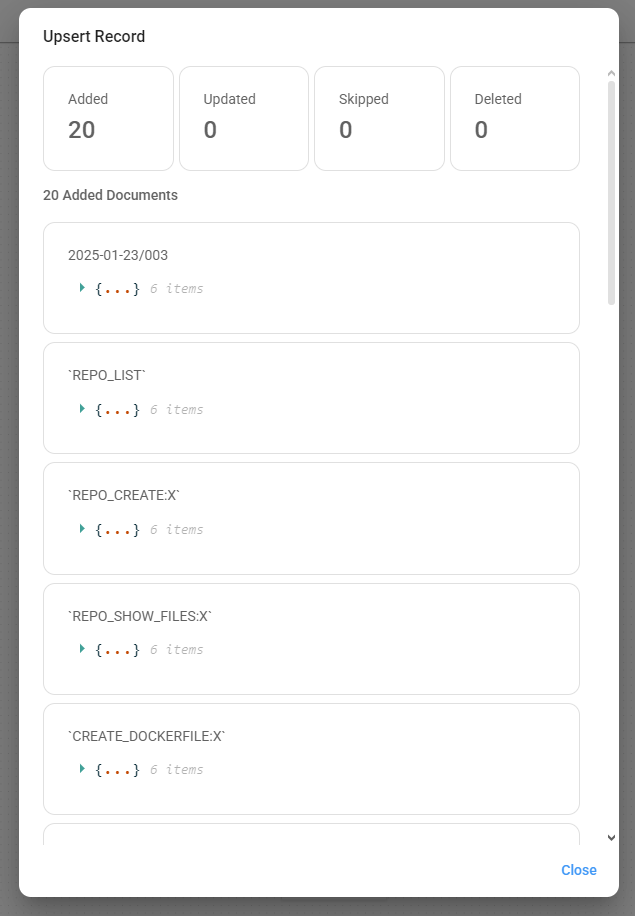
- Нажмите на кнопку Upsert Vector Database. Дождитесь завершения внедрения.
Процесс внедрения может занять длительное время, в зависимости от размера набора данных и производительности компьютера.
- Запустите новый чат чтобы проверить, как это работает.
Хорошей практикой является указание подсказки для введения модели в контекст.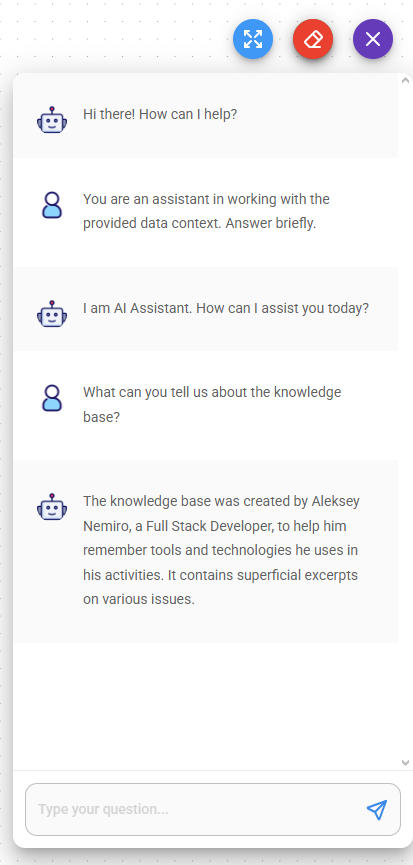
- Наслаждайтесь!