llama-server
warning
This document has been translated using machine translation without human review.
The llama.cpp library makes it easy to deploy a server with a web interface:
llama-server -m "C:\models\Codestral-22B-v0.1-Q4_K_M.gguf" --port 8080
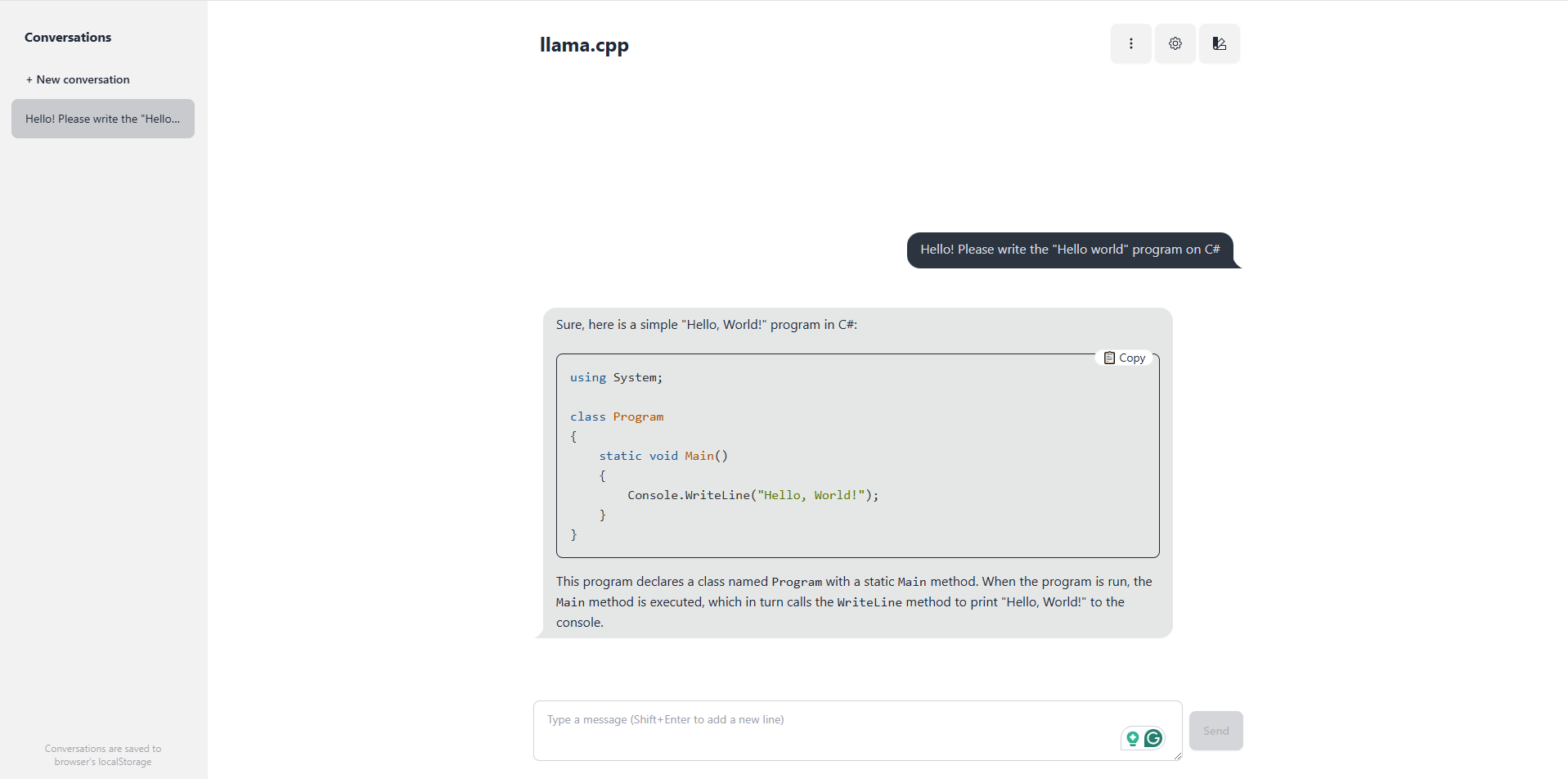
Multi-user support
For example, 4 users with a maximum context window of 4096 x 4 = 16,384:
llama-server -m phi-4-Q4_K_M.gguf -c 16384 -np 4 --port 8080
Embedding
The server can be run in embedding mode. In this case, the server performs data vectorization.
The embedding server can be used for RAG (Retrieval-Augmented Generation).
The following example shows how to start the server in embedding mode:
llama-server -m "C:\models\phi-4-Q4_K_M.gguf" --embedding --pooling cls --ubatch-size 8192
--pooling— specifies the pooling type for embedding:- none — no pooling/grouping;
- mean — averaging of vector representations, this type is used most often;
- cls — a special token added to the beginning of each word for classification. Used in BERT and derivative models. Optimal for QA (question-answer) tasks;
- last — uses the vector representation of the last token or word from the sequence;
- rank — a ranking or selection method based on certain criteria.
--ubatch-size— the maximum batch size in bytes (default is512). The optimal value is determined experimentally.