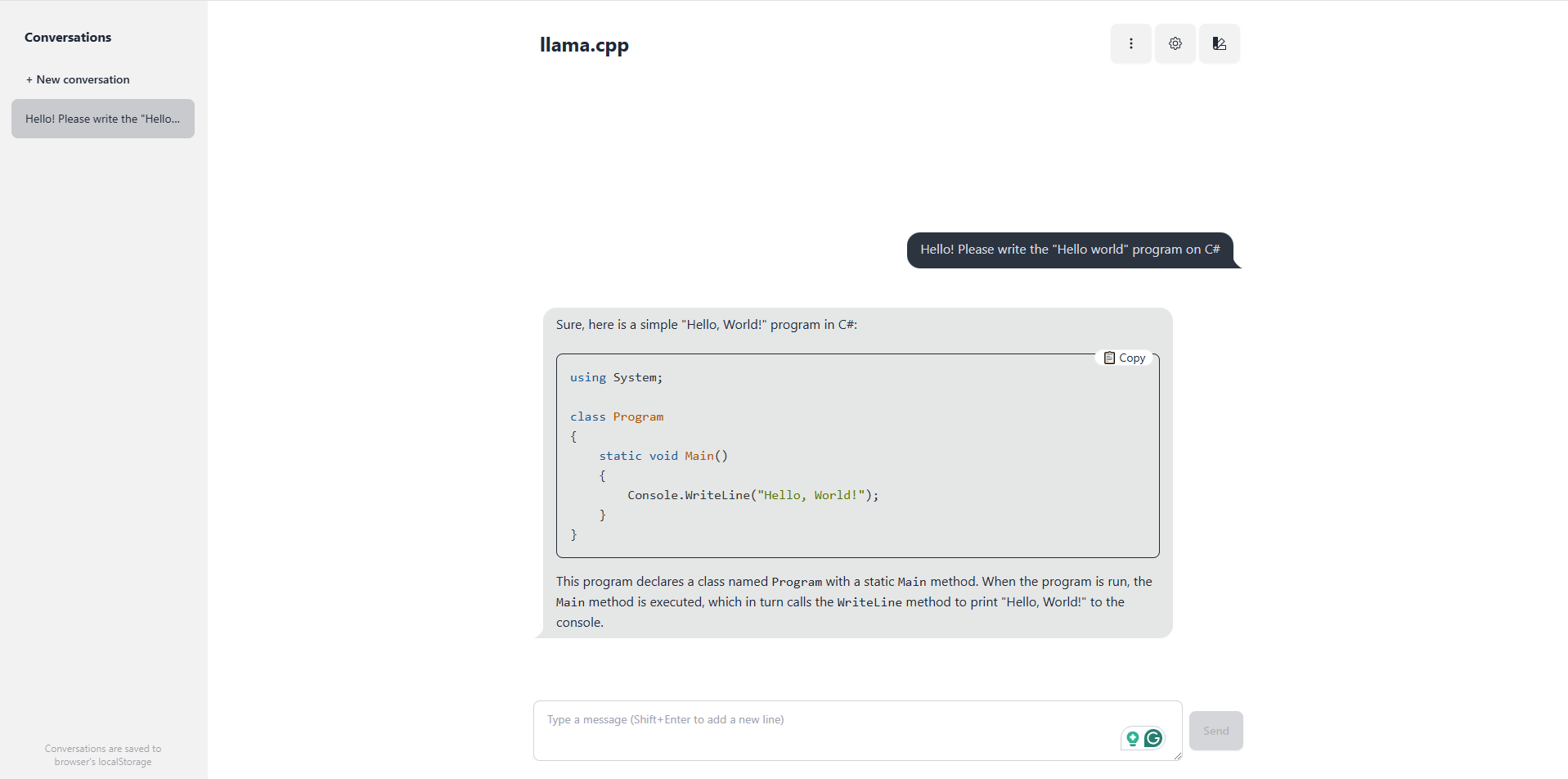
llama-server
Библиотека llama.cpp позволяет легко развернуть сервер с веб-интерфейсом:
llama-server -m "C:\models\Codestral-22B-v0.1-Q4_K_M.gguf" --port 8080
Многопользовательская поддержка
Например, 4 пользователя с максимальным окном контекста 4096 x 4 = 16 384:
llama-server -m phi-4-Q4_K_M.gguf -c 16384 -np 4 --port 8080
Внедрение (embedding)
Сервер можно запустить в режиме внедрения. В этом случае, сервер выполняет векторизацию данных.
Сервер внедрения можно использовать для RAG (Relative-Augmented Generation).
В следующем примере показан вариант запуска сервера в режиме внедрения:
llama-server -m "C:\models\phi-4-Q4_K_M.gguf" --embedding --pooling cls --ubatch-size 8192
--pooling— задаёт тип группировки для внедрения:- none — без объединения/группировки;
- mean — усреднение векторных представлений, этот тип используется чаще всего;
- cls — специальный токен, добавляемый в начало каждого слова для классификации. Используется в BERT и производных моделях. Оптимален для задач QA (вопросы-ответы);
- last — использует векторное представление последнего токена или слова из последовательности;
- rank — метод ранжирования или отбора на основе определенных критериев.
--ubatch-size— максимальный размер пакета в байтах (по умолчанию —512). Оптимальное значение подбирается экспериментально.